训练硬件 Custom Device 接入方案介绍¶
如果硬件采用侵入式(Built-in)方案接入飞桨框架,代码开发量大,并且需要对飞桨框架的架构和设计有一定了解,对硬件适配的开发者技能要求高,硬件接入成本高。因此飞桨推出了 Plugin 可解耦插件式(Custom Device)硬件接入方式,通过对框架的核心功能与硬件运行时进行分离、框架模块之间的标准接口设计,减少新硬件接入的深度集成工作量的同时,保持多硬件环境组合的灵活性。硬件如果要接入飞桨训练框架和 Paddle Inference 原生推理框架,推荐采用本章介绍的方案。
一、硬件接入整体设计¶
为了实现可解耦插件式硬件接入,飞桨框架抽象出了“硬件接入层”和“虚拟设备层”,并对外提供了标准接口,开发者无需为特定硬件修改飞桨框架代码,只需实现标准接口,并编译成动态链接库,则可作为插件供飞桨框架调用。降低为飞桨框架添加新硬件后端的开发难度。
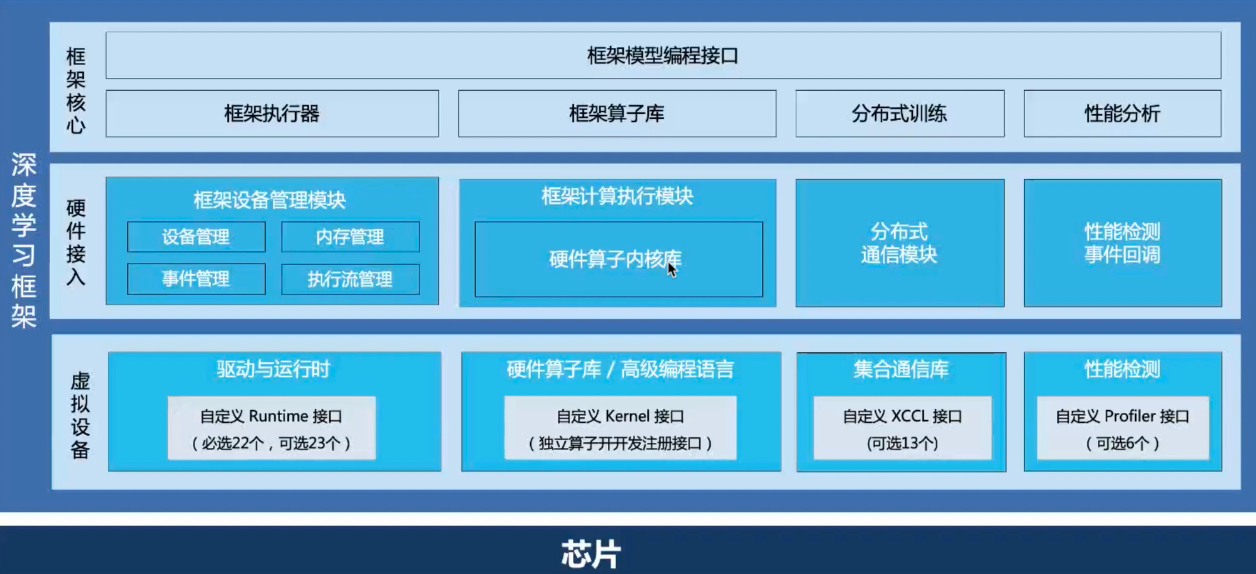
硬件接入层:将硬件接入相关的功能模块和框架的主体核心功能解耦,比如设备管理上将 DeviceManager 模块抽象出来,分布式通信上将 ProcessGroup 模块抽象出来,整体和硬件相关的框架功能都变得独立化和模块化。
虚拟设备层:飞桨框架内部注册了一个 customdevice 虚拟设备,在真实的底层芯片和框架中间做了一层隔离,虚拟设备层里面的所有功能接口都是可注册的函数指针,适配方式从原来的侵入式对接变成了插件式的对接。其作用是一方面是将硬件接入层提供的接口开放出来,另一方面是屏蔽框架升级变动对硬件接入的影响,飞桨框架内部有任何功能或者架构上的升级变化,飞桨的框架开发者都会将最新的功能和 customdevice 进行适配升级,那么所有通过 customdevice 的接口来接入飞桨的硬件都会无缝切换到飞桨最新功能,硬件侧的适配接口和适配代码都是无感知的。开放的标准接口也保持长期稳定,硬件厂商无须重复适配。
另外飞桨在接口设计上也充分考虑了各个硬件之间 SDK 的差异,因此可以看到必选的接口是很少的,大部分都是可选接口,硬件可以根据自身 SDK 的不同设计自由选择对应的接口进行注册。
目前采用该方案接入飞桨框架的硬件包括 华为昇腾 NPU、寒武纪 MLU 等多款芯片,经实践证明,新硬件完成初次适配(即单个算子在新的硬件上成功执行)大约仅需一周时间,大大降低硬件接入成本。
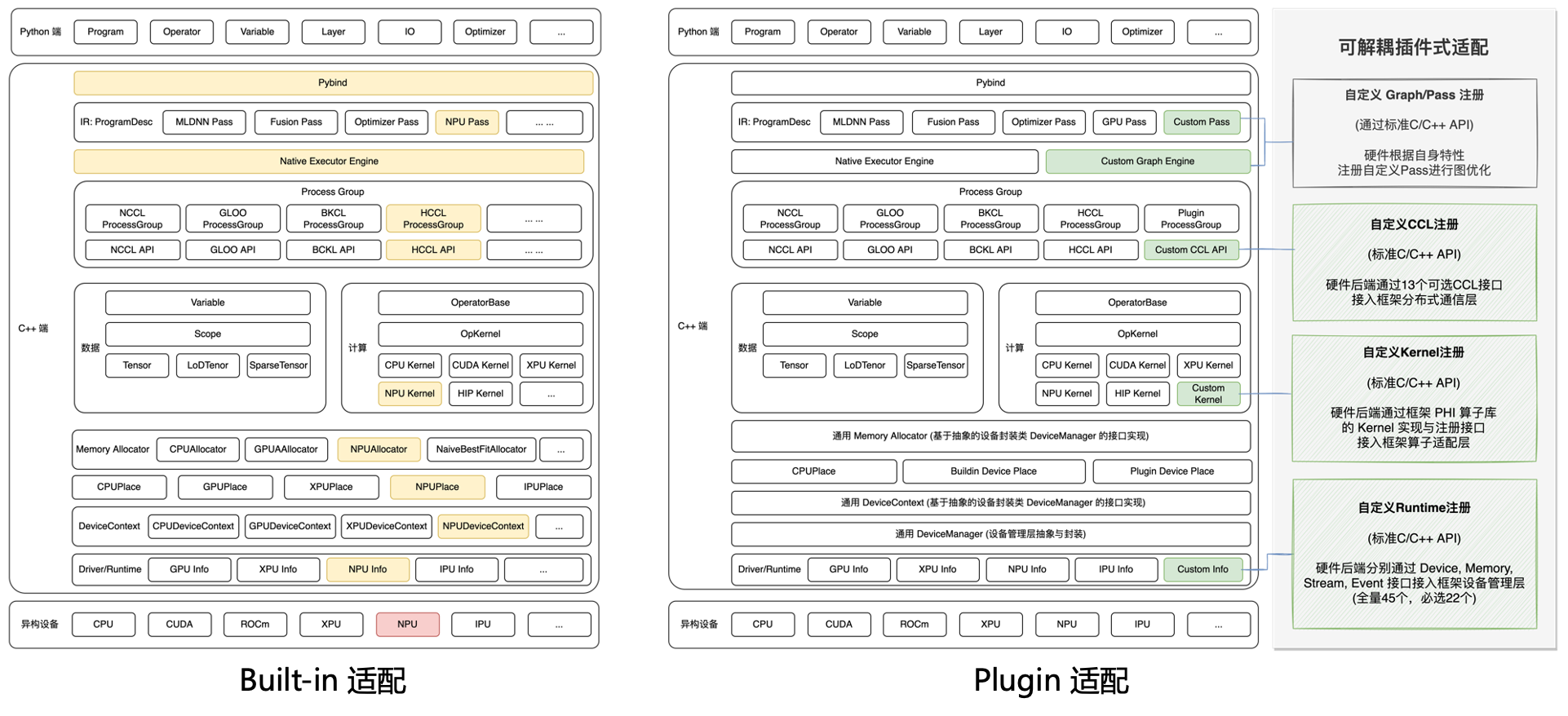
侵入式(Built-in)和插件式(Plugin)两种方案的整体设计框架对比如下图所示,接下来介绍 Plugin 适配方案中各个功能模块的详细设计。
自定义 Runtime 注册:提供标准 C/C++ API,供硬件 SDK接入飞桨框架的设备管理层。
自定义 Kernel 注册:提供标准 C++ API,供硬件算子实现接入飞桨框架的算子适配层。
自定义 CCL 注册:提供标准 C/C++ API,供硬件 SDK 的 Collective 通信库接入飞桨框架的分布式模块。
说明:Plugin 适配方案正在持续扩展功能模块,比如自定义 Graph/Pass,提供图编译执行引擎接口;自定义 Profiler,提供性能采集接口。这些将在后续版本中补充。
二、自定义 Runtime 注册模块的设计¶
自定义 Runtime 注册模块,支持硬件通过函数注册的方式来接入硬件 SDK(包括 Driver+Runtime),向上(框架层)提供 Plug-in 设备的生命周期管理,向下(硬件层)提供统一的抽象接口函数,使得 Plug-in 设备可被飞桨框架识别为框架内的一种硬件类型。
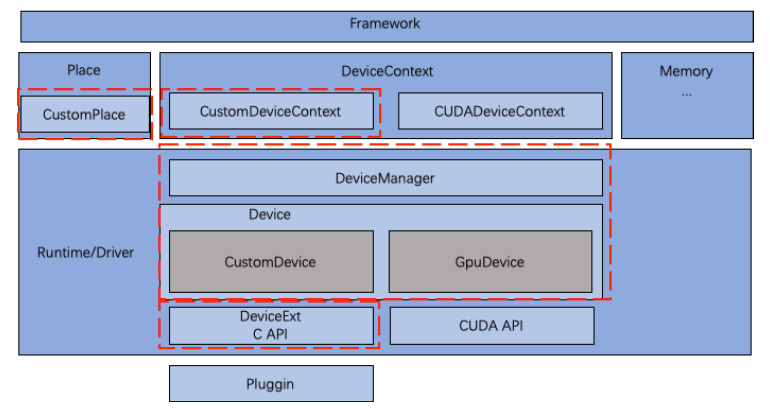
飞桨框架添加了一层 Device 对硬件 SDK 的 API 进行封装,用于框架和硬件的解耦,封装的硬件 SDK API 包括:
Device 管理:包括 Device 获取/加载/释放,指定/获取设备号,设置运行选项/参数等。
Context 管理:包括 Device Context 创建/销毁、设置/获取等,支持隐式和显式两种方式。
Stream/Event 管理:包括 Stream/Event 的创建/销毁、设置/获取、同步/阻塞和回调等。
内存管理:包括 Device 内存的申请/释放/初始化,Host 与 Device 之间的内容拷贝等。
新硬件与飞桨框架通过 DeviceExt C API 进行耦合,只有 DeviceExt C API 相关代码改动时才需要改动新硬件的代码。
硬件注册逻辑如下图所示:
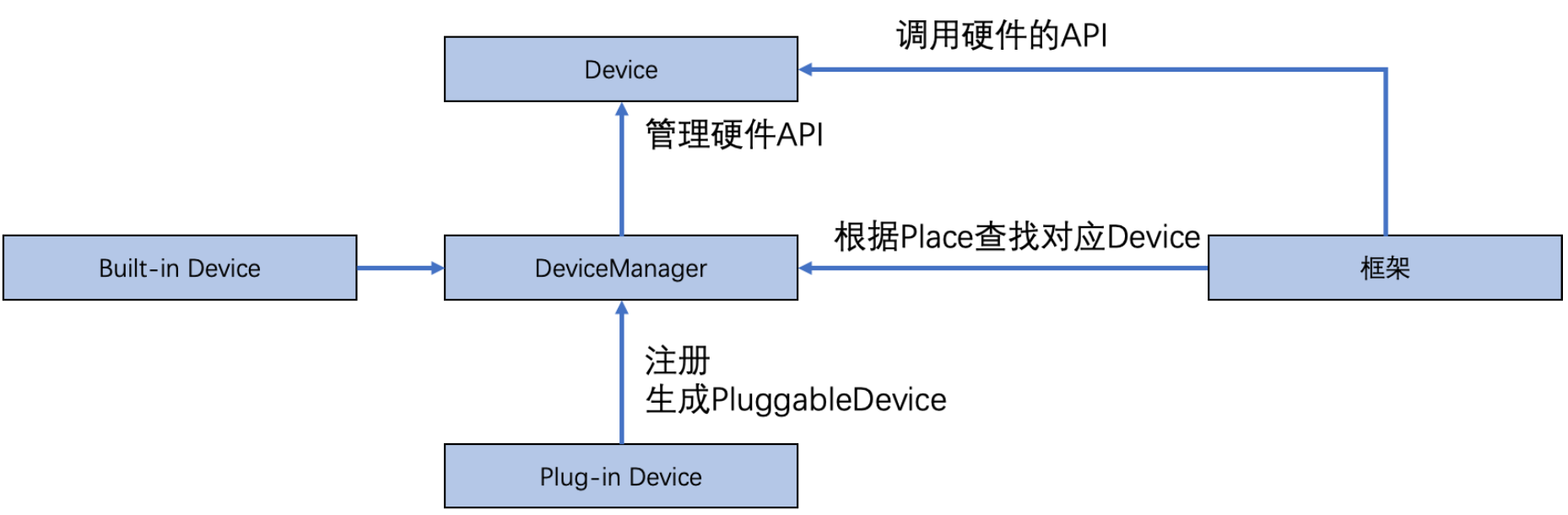
Device 封装底层 Runtime/Driver API,DeviceManager 管理 Device,框架通过 Place 可以找到对应的 Device。
Built-in 硬件在初始化时会构造对应 CpuDevice、 CudaDevice 对象注册到 DeviceManager。
Plugin 硬件在初始化时会构造一个 CustomDevice 对象注册到 DeviceManager。
CustomDevice 的 Runtime 函数接口分为 5 类,设备管理,Stream 管理,Event 管理,内存管理和信息查询,详细介绍请参见 API 参考文档。
三、自定义 Kernel 注册模块的设计¶
内核函数(简称 Kernel)对应算子的具体实现,飞桨框架针对通过自定义 Runtime 机制注册的硬件,提供了配套的自定义 Kernel 机制,以实现独立于框架的 Kernel 编码、注册、编译和自动加载使用。
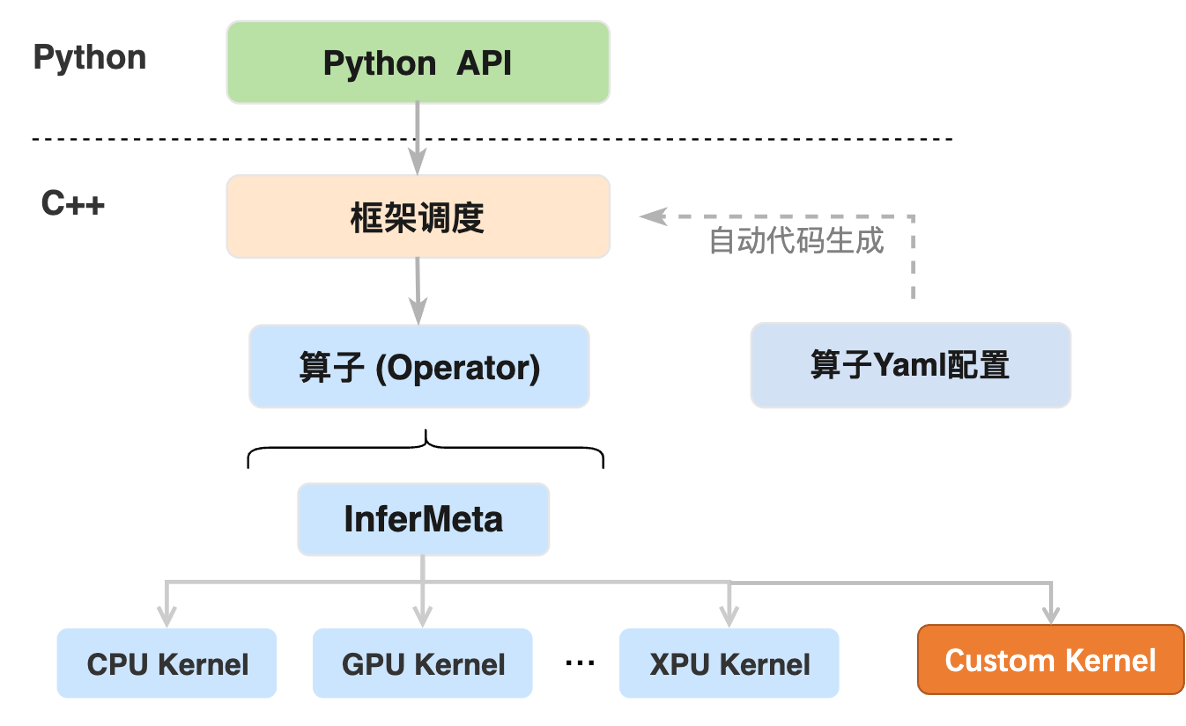
飞桨框架提供了 Custom Kernel 模块,可独立于飞桨框架进行硬件 Kernel 编码,并接入飞桨框架的高可复用算子库 PHI,以实现飞桨框架对新接入硬件算子的统一调度和执行:
Python API 执行时会进入到 C++ 端由框架进行调度并执行相应的算子逻辑,算子的执行主要包括两个过程:
(1)执行算子 InferMeta 函数完成输出结果的维度、数据类型等静态信息的推导。
(2)根据输入变量的设备信息选择对应的硬件设备来执行算子 Kernel,完成输出结果的数值计算。
Python API 到算子 InferMeta 函数和 Kernel 调用之间的框架调度部分的逻辑代码主要通过算子 Yaml 配置中的信息自动生成,也可以理解为算子 Yaml 配置的作用是通过自动代码生成将上层 Python API 与底层算子的 Kernel 建立连接。
Custom Kernel 定义的标准接口,详细请参见 API 参考文档。
四、自定义 CCL 注册模块的设计¶
自定义 CCL 注册模块,在飞桨框架现有分布式通信模块基础上,添加右侧浅⻩色的 ProcessGroupCustom 类以支持新硬件,硬件 SDK 只需要通过 CustomCCL API 定义的标准 C/C++接口,实现 ProcessGroupCustom 中的具体功能函数,即可接入飞桨框架的分布式通信功能模块,从而支持飞桨分布式训练功能。该方案目前支持集合通信 Collective 模式,不支持参数服务器 PS 模式。

本方案主要修改和新增以下模块:
CustomCCL:提供标准的 C/C++接口,供第三方硬件后端接入。
ProcessGroupCustom:继承自 ProcessGroup,实现了基类的所有功能函数。
Collective Ops/Collective Kernels:实现静态图所需的分布式通信库的 OP 和 Kernel。
ParallelEnv:Python 端接入新的 CustomCCL 作为 backend 进行调用。
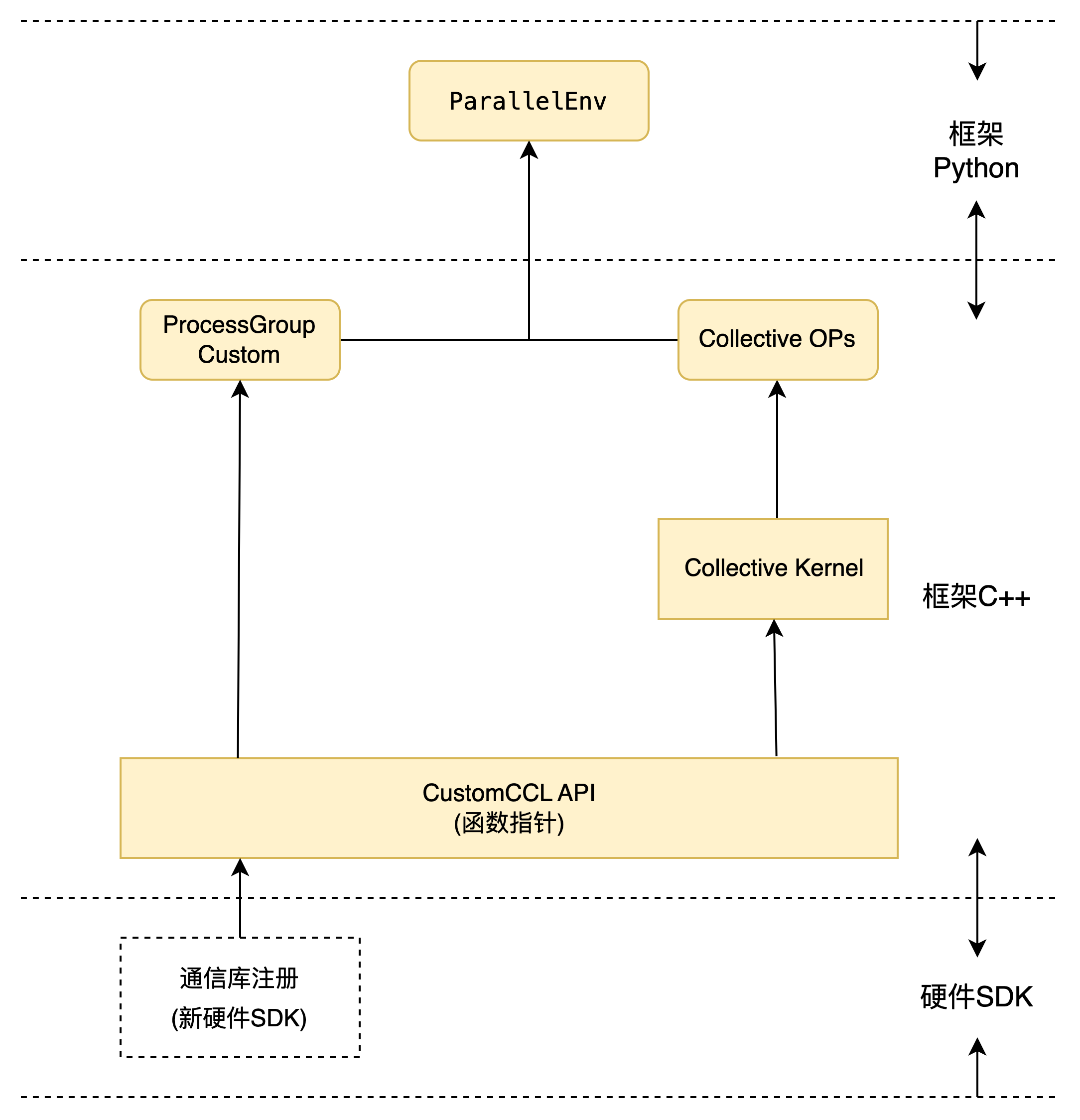
ProcessGroupCustom 继承自 ProcessGroup,是实现动态图模式下通信与计算、通信间的依赖关系管理的重要模块,其中的集合通信操作接口通过 CustomCCL 开放出去;静态图模式下,则是通过调用 Collective Ops / Collective Kernels,由静态图执行器调度执行。
ProcessGroup 用于描述建立在指定后端上的通信组和该通信组内可以执行的通信方法,是对通信操作所涉及范围的一个逻辑和物理划分,在同一个通信组中的进程会在指定后端上执行对应的通信操作。在复杂的混合并行策略中,会根据不同的并行策略,创建多个通信组。在建立通信前,同一个通信组中的进程需要交换通信相关的信息(和具体硬件相关,比如 ncclUniqueID),并根据唯一 ID 创建对应通信组唯一 Comm(如 ncclComm),之后的所有在该通信组中的通信操作,都会在对应的通信 Comm 上进行。
ProcessGroup 中包含一系列集合通信操作的接口(如 AllReduce、AllGather 等),用于做流间依赖管理的 Task 机制(Event、Stream)。其中集合通信操作的实现会调用 CustomCCL 对应的集合通信 API,进而由 CustomCCL 根据硬件类型,通过 device_manager 选择正确的硬件和对应的计算实现。
CustomCCL 定义的标准接口,详细请参见 API 参考文档。